

One of the new functionalities in Acropolis Operating System, formerly known as both Acropolis Base Software and Nutanix Operating System (NOS) version 4.5, is the ability to enable both compression and deduplication on the same Nutanix Container. This blog post explains existing Nutanix nomenclature. The purpose of this blog post is to give you a short description of the Distributed Storage Fabric (DSF) features compression & deduplication and explain what happens when both features are enabled on the same container.
Compression overview
The DSF compression feature can compress data during or after a write operation and therefore there are two types of compression available.
- Inline compression: Data is compressed as it is written.
- Post-process compression: Data is compressed after it is written.
Inline compression is managed differently for random and sequential writes.
- Compression of random writes happens after the write is acknowledged to the virtual machine (VM).
- This means after it is written to Nutanix oplog space which is staging area for random data but before the data is moved to the extent store (persistent data storage in Nutanix).
- Compression of sequential writes occurs in the Controller Virtual Machine (CVM) random access memory (RAM) and is then written directly to the Nutanix Extent Store.
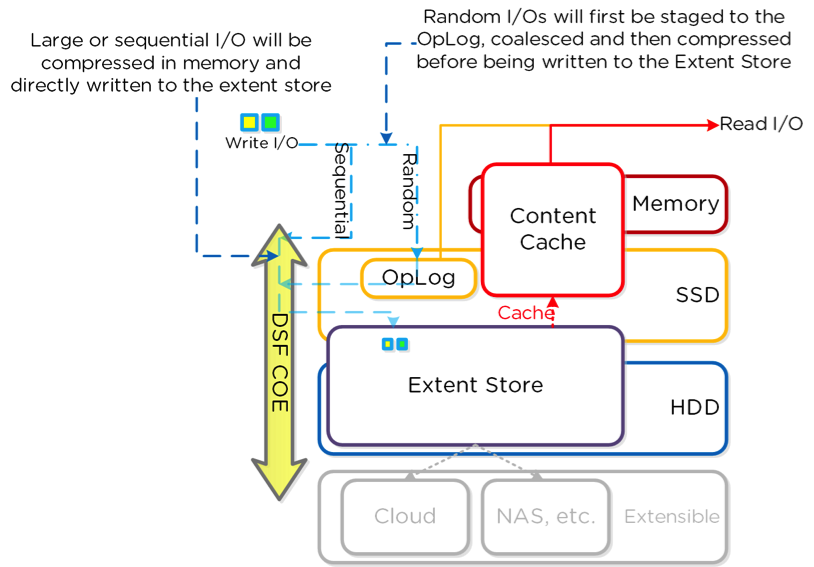
The above picture shows the I/O path for inline compression.
Post-process compression happens on uncompressed data in the extent store. You can tune the amount of time before initiating compression to best fit your potential workload.
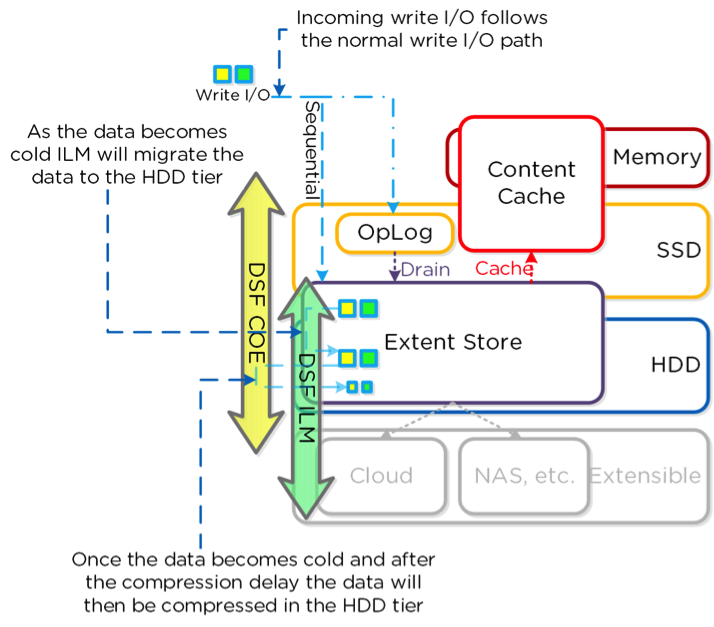
The above picture shows the I/O patch for post-process compression
Deduplication overview
Another feature of DSF is the Nutanix Elastic Deduplication Engine, a software-driven, massively scalable, and intelligent data reduction technology. By eliminating duplicate data, the engine increases the effective capacity in the disk tier, as well as the system’s RAM and flash tiers. The larger effective cache capacity in RAM and flash substantially increases storage efficiency, while also improving performance.
There are two deduplication options available:
- Performance-trier deduplication – Will improve caching and achieve faster reads and same time use less RAM and SSD. The cache is per CVM.
- Storage-tier deduplication – Will decrease storage utilization by deleting duplicate blocks on the extent store (backed by both SSD and HDD). On disk deduplication is global among all Nodes in the Nutanix cluster.
Performance-trier deduplication can be used without on Storage-tier deduplication but not the other way around.
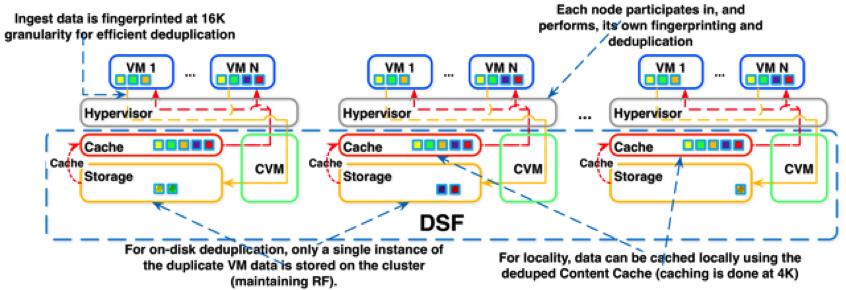
The above picture shows the elastic deduplication engine
Each CVM in the Nutanix cluster participates in the deduplication process making fingerprints and storing each fingerprint in the VM data metadata. When the MapReduce process removes duplicate data at the Nutanix cluster HDD layer, it does not have to read all data; reading the metadata is sufficient to determine duplicate blocks. This capacity dramatically reduces CPU cycles. Deduplicated data is pulled into the content cache (backed by RAM and SSD) using 4KB block size.
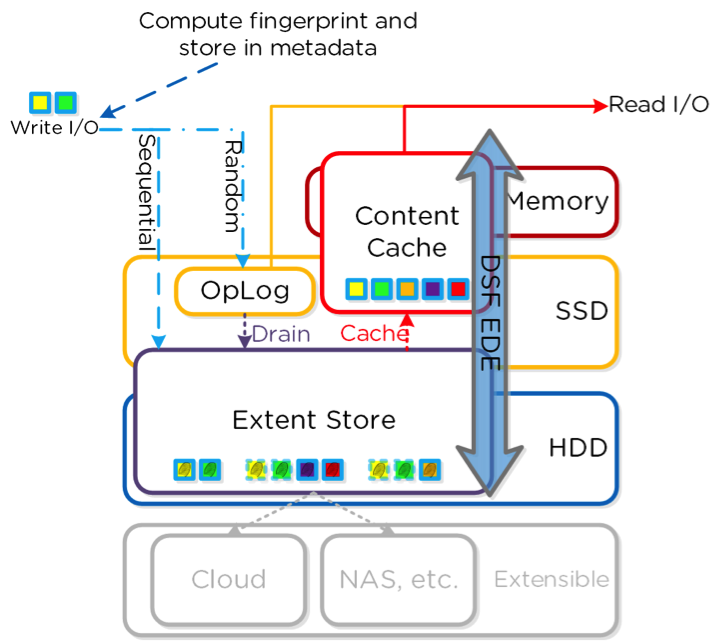
The above picture shows deduplication
Compression and deduplication on the same Nutanix Container
As mentioned before we can now, since Acropolis base Software version 4.5 enable both compression and deduplication on the same Nutanix Container.
The below print screens shows the features enabled on a Nutanix Container not including any data, they are just there to give you an idea of how it will look in the PRISM UI.
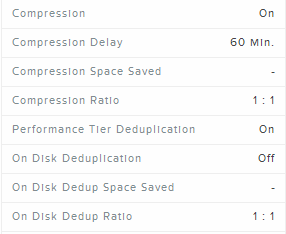
Compression and Performance-trier deduplication enabled
In this case there are two different options available:
- Inline compression
- Data will be compressed and fingerprinted the same time when it is written.

- Data will be compressed and fingerprinted the same time when it is written.
- Post Process Compression
- Data is fingerprinted during the initial write.
- Data is marked for compression X minutes (according to the configuration) after it has been written.
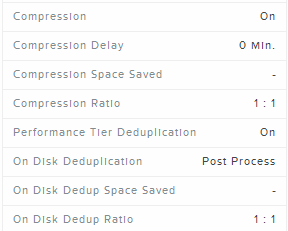
Compression and Storage-tier deduplication enabled
As mentioned earlier fingerprinting must be enabled to take advantage of on-disk deduplication so donate get confused by the heading.
In this case there are also two different options available:
- Inline Compression
- Data will be compressed and fingerprinted the same time when it is written.
- On-disk deduplication happens at a later time as a background process.
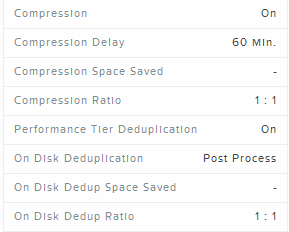
- Post Process Compression
- Data is fingerprinted during the initial write.
- Data is compressed and deduped at a later time as a background process.
3 pings