
- Acropolis Virtual Machine High Availability – Part I
- Acropolis Virtual Machine High Availability – Part II
Over the years I have updated the blog post once every now and then and recently I decided to create an official Nutanix Technical paper about it. Reason being the increasing number of questions around it which I think is because more and more people (Nutanix customers and partners & so on) are looking into Nutanix AHV.. This blog post is based on the official document.
There are three sections in the blog post:
- Nutanix AHV Virtual Machine High Availability – Introduction
- Nutanix AHV Virtual Machine High Availability – Calculation
- Nutanix AHV Virtual Machine High Availability – Failure Detection
Reason being the increasing number of questions around it which I think is because more and more people (Nutanix customers and partners & so on) are looking into Nutanix AHV.
Virtual Machine High Availability Introduction
Virtual machine high availability (VMHA) ensures that VMs restart on another AHV host in the AHV cluster when the AHV host where the VM is running becomes unavailable which includes:
- The AHV host has a complete failure
- The AHV host becomes network partitioned
- The AHV host management process failure.
When the AHV host where a VM is running becomes unavailable, the VM powers off, and is powered on again on another AHV host.
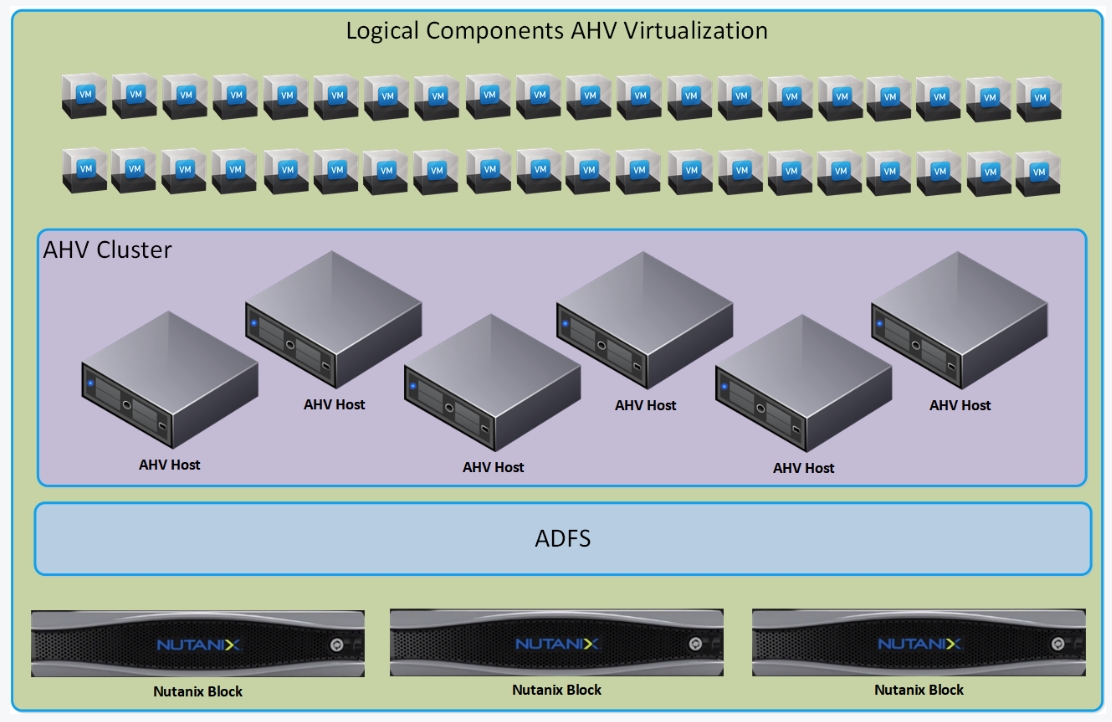
The following components are addressed throughout the blog post.
- AHV cluster – Logical grouping of AHV hosts that provides services for VMs.
- Acropolis Distributed Storage Fabric (Acropolis DSF) – Nutanix storage layer.
- Nutanix node – An individual physical server, without specifying a hypervisor.
- AHV host – An individual physical server running AHV as the hypervisor.
- Nutanix block – The 1RU (rack unit) or 2RU chassis where an AHV host is physically located. Depending on the node model, a Nutanix block can hold up to four Nutanix nodes.
Virtual machine high availability comes in two modes:
- Default – This mode requires no configuration and is included by default when installing an AHV-based Nutanix cluster.
- Guarantee – This mode reserves space throughout the AHV hosts in the cluster to guarantee that all VMs can restart on other hosts in the cluster when an AHV host becomes unavailable. The method to achieve this is called ReserveSegments (name used via acli is kAcropolisHAReserveSegments)
Virtual machine high availability sets aside compute resources for one AHV host failure if all Nutanix containers are configured with replication factor (RF) 2 and for two AHV host failures if any Nutanix container is configured with RF3.
Virtual Machine High Availability respects Acropolis Distributed Scheduler (ADS) VM-host affinity rules, but it may not honor VM-VM anti-affinity rules, depending on the scenario.
Virtual Machine High Availability Calculation
Every time a VM is powered on in the AHV cluster it performs a calculation which from a high level perspective includes the following:
- Assign the VM a Parcel, which is a logical unit defining the resources required by the VM to run.
- Make sure the VM can run on the target AHV host
- Make sure the VM can run on any other AHV host in the cluster
- Respect previous calculations meaning all other VMs already running in the cluster can run on another AHV host in the cluster if their AHV host fails.
Specific VM requirements such as VM-host affinity & GPU are respected when the calculation is taking place.
Important: A VM parcel takes away resources from the AHV host where it is running and from the AHV host holding the failover segment. You can map multiple parcels to the same AHV host failover segment if the parcels belongs to VM/VMs running on different AHV hosts.
Let’s provide a few examples for a three node AHV host cluster where the hosts provides same amount of memory. More examples can be found in the Nutanix official Virtual Machine High Availability document.
Starting with no VMs running in the cluster we see that each AHV host has 100% of its resources available to run VMs.

Powering on the first VM in the cluster, VM01, which takes 70 % of an AHV host’s resources we take out 70% of the resources from the AHV host 1 where the VM is powered on and also Segment resources from any other AHV host, in this case AHV host 2. If/when AHV Host 1 fails VM01 can start on AHV Host 2 meaning we guarantee failover functionality for VM01.
After VM01 is powered on the following resources to run VMs are available per AHV host:
- AHV host 1 = 30%
- AHV host 2 = 30 %
- AHV host 3 = 100%

Building on the above example we now start two more VMs, VM02 and VM03 which both takes 40% of an AHV host available resources. Since AHV host 2 holds a segment for VM01 which takes 70% of it’s resources it only has 30% available resources for running VMs meaning neither VM02 or VM03 fits on AHV host 2.
However, powering on both VM02 and VM03 on AHV host 3 works since it has 100% free resources.
After VM02 and VM03 are powered on the following resources to run VMs are available per AHV host:
- AHV host 1 = 30%
- AHV host 2 = 20 % (Must take largest segment or sum of segments from any remote AHV host away from the AHV host capacity to run VMs)
- AHV host 3 = 20%

Virtual Machine High Availability Failure Detection
This section is pretty much unchanged compared to the initial blog post but I’ll present it here anyway so you’ll have all information available at one place.
The Acropolis master process/service which runs in one of the CVMs in the cluster monitors cluster state and triggers actions in the AHV cluster when an AHV host becomes unavailable. All CVMs in the cluster runs an Acropolis process/service but only one is the master, the rest act as subordinates.
Every second the Acropolis master sends communication between itself and each AHV host’s libvirtd process to detect failures. So the communication is not between CVMs in this case, important to understand.
If this communication fails and is not reestablished within X seconds (the number of seconds depends on the failure scenario), VMHA initiates a failure process.
Remote AHV Host Is Unavailable
| Time in Seconds | Description |
|---|---|
| T- | Normal operation: Acropolis master can complete health checks against all remote AHV hosts’ libvirtd processes successfully. |
| T0 | Acropolis master loses network connectivity to a remote AHV host’s libvirtd process. |
| T20 | Acropolis master starts a 40-second timeout. |
| T60 | Acropolis master instructs all CVM Stargate processes to block I/O from the AHV host with lost connectivity. Acropolis master waits for all remote CVM Stargate processes to acknowledge the I/O block. |
| T120 | All VMs restart. Acropolis master distributes the VM start requests to the available AHV hosts. |
Remote AHV Host Network Partitioned
| Time in Seconds | Description |
|---|---|
| T- | Normal operation: Acropolis master can complete health checks against all remote AHV hosts’ libvirtd processes successfully. |
| T0 | Acropolis master loses network connectivity to a remote AHV host’s libvirtd process. |
| T20 | Acropolis master starts a 40-second timeout. |
| T60 | Acropolis master instructs all CVMs’ Stargate processes to block I/O from the AHV host with lost connectivity. Acropolis master waits for all remote CVM Stargate processes to acknowledge the I/O block. Because all I/O is blocked, the VMs can’t make any progress on the network partitioned AHV host, so it’s safe to continue. The VMs on the network partitioned AHV host terminate 45 seconds after the first failed I/O request. |
| T120 | All VMs restart. Acropolis master distributes the VM start requests to the available AHV hosts. |
Acropolis master failure
| Time in Sec | Description |
|---|---|
| T- | Normal operation: Acropolis master can complete health checks against all remote AHV hosts’ libvirtd processes successfully. |
| T0 | The AHV host running the CVM which holds the Acropolis master becomes unavailable. |
| T20 | The remaining available AHV hosts elect a new Acropolis master. |
| T60 | The new Acropolis master instructs all CVMs’ Stargate processes to block I/O from the AHV host where the original Acropolis master ran. Acropolis master waits for all remote CVM Stargate processes to acknowledge the I/O block. |
| T120 | All VMs restart. Acropolis master distributes the VM start requests to the available AHV hosts. |
That’s it – hope you got a better understanding of how AHV cluster Virtual Machine High Availability works.
Click Virtual Machine High Availability to reach the official document – Nutanix Portal login required.